深度解析 KWeaver Core 如何实现非结构化数据的高可靠问答

摘要:在企业级非结构化数据问答中,从"能用"到"可靠"的跨越,面临着证据链断裂、多跳推理发散等严峻挑战。本文深入剖析了我们如何通过构建 AI Data Platform (KWeaver Core),将传统的检索增强生成(RAG)升级为一种平台化的上下文工程(Platform-based Context Engineering)。通过解构其核心组件、分享关键的消融实验数据,我们展示了如何通过业务知识网络、精确的工具治理和动态上下文加载,实现高可靠通过率,显著超越业界主流方案。
文章贡献者:燕楠、许鹏、陈储培
1. 引言:当"能用"不再足够
在过去的一年里,RAG 技术使得让 LLM"基于文档说话"变得唾手可得。然而,当我们试图将这一技术应用于复杂的企业内部非结构化数据(如多格式简历、技术规范等)时,我们撞上了一堵"可靠性之墙"。
RAG 的核心在于为大模型提供高质量的上下文,但在实际的企业场景中,构建高质量上下文面临着四重挑战:
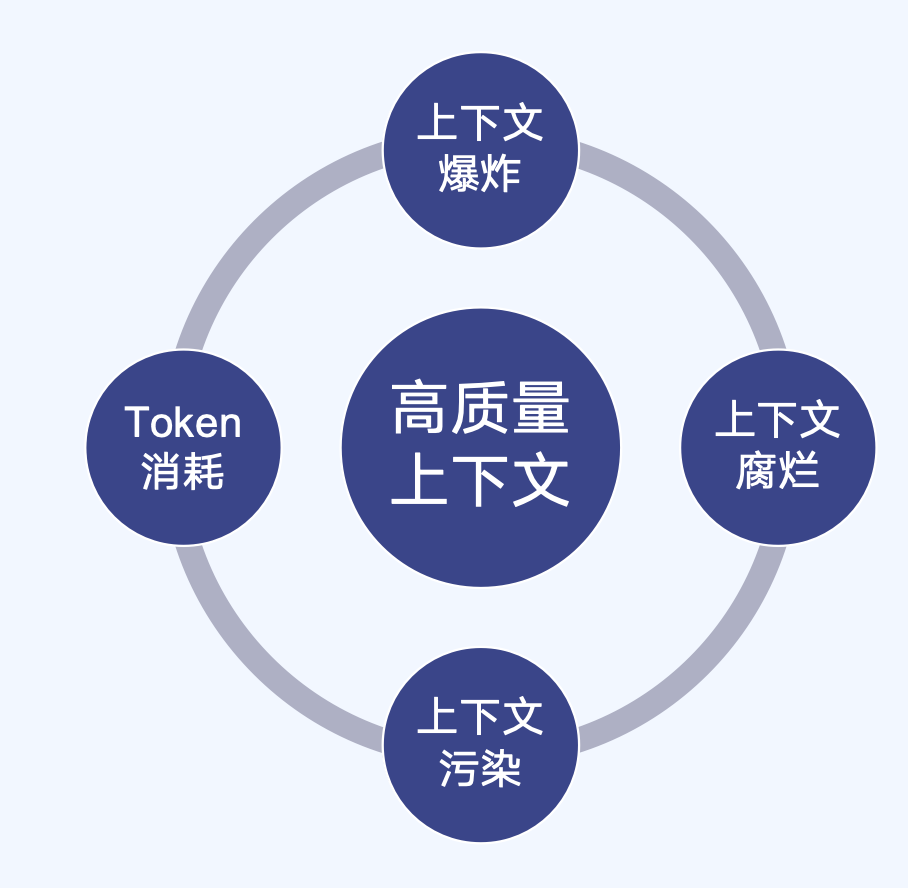
- 上下文爆炸:企业文档体量庞大、格式多样,检索返回的候选片段数量激增,远超模型的有效处理能力,导致关键信息被淹没在海量噪声中。
- 上下文腐烂:企业数据处于持续更新状态,传统的 ETL 批量导入模式导致知识库与源数据之间存在时间差,智能体可能基于过时信息进行推理。
- 上下文污染:检索召回的片段中混入了不相关或误导性的内容,这些"噪声"会干扰大模型的判断,引发幻觉或错误推理。
- Token 消耗:将大量检索结果注入上下文窗口会带来显著的 Token 开销,不仅增加响应延迟和成本,还可能因超出窗口限制而被迫截断关键证据。
在早期测试中,我们发现传统的 RAG 架构(简单的 chunking + 向量检索)本质上只能匹配字面语义相似度,无法理解文档间的逻辑与业务链路。上述四重挑战叠加后,在面对以下稍微复杂的业务场景时更显得力不从心:
- 跨段落的隐式关联:答案分散在文档的多个板块中,且缺乏显式的关键词链接,传统向量距离无法跨越这道鸿沟。
- 需要领域知识的推理:智能体不理解特定行业的术语或业务实体之间的逻辑关系,无法将散落的片段串联起来。
- 执行路径的发散:面对复杂问题,智能体容易在过多的工具中迷失,导致推理步数爆炸甚至死循环。
我们的目标非常明确:在这些复杂场景下,不仅要提供答案,还要提供确定性。为了达成这一目标,我们构建了 AI Data Platform (KWeaver Core)——一个不仅存储数据,更存储数据"语义"和"连接"的智能操作系统。
2. KWeaver Core 架构:为智能体构建的"语义操作系统"
KWeaver Core 的设计哲学是:不是让智能体直接面对原始数据,而是为它提供一个结构化的、语义丰富的操作环境。
下图展示了 KWeaver Core 的核心架构。它通过 VEGA 引擎虚拟化集成多源数据,通过数据流(Dataflow)处理非结构化数据到业务知识网络,再通过 BKN(业务知识网络)建立语义连接,最后通过 Context Loader 为智能体按需加载上下文信息。
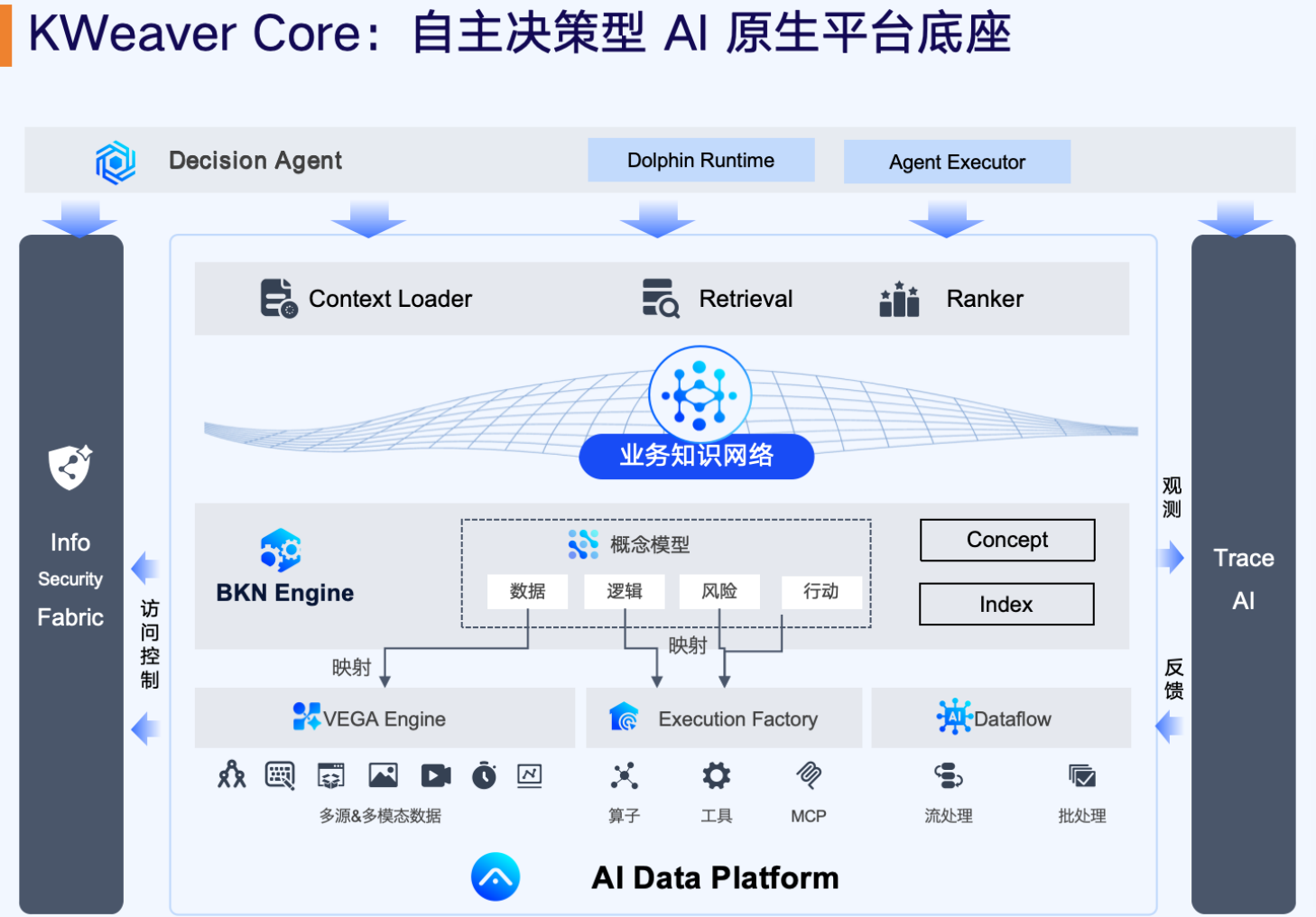
2.1 核心组件深挖
- BKN (Business Knowledge Network, 业务知识网络):这是 KWeaver Core 的核心。它不仅是企业语义关系的结构化表示,更是一种将企业的实体、关系、甚至业务逻辑(如"候选人的'技能标签'与'项目经验'存在关联关系")建模为机器可理解网络的引擎。它为智能体提供了推理的"地图"。
- VEGA(VEGA Data Virtualization, VEGA数据虚拟化):解决了数据孤岛问题。它实现了对结构化、非结构化、多模态数据的零复制(Zero-copy)实时集成。这一特性避免了繁重且易滞后的 ETL 数据搬运过程,确保智能体看到的是最新、最全的数据视图。
- Dataflow(数据流):它是非结构化数据转化为语义网络的桥梁,负责处理非结构化数据到业务知识网络。它通过解析与信息抽取等手段将杂乱无章的文档文本、图表等转化为 BKN 内的结构化实体与关系。
- Context Loader (上下文加载器):这是提升准确率的关键组件。传统的 RAG 只是通过向量检索文本片段,而 Context Loader 在此基础上实现了多层能力增强:
- 语义重排(Semantic Reranking):对初步检索到的候选片段,通过 Cross-Encoder 模型进行精排,依据语义相关度而非单纯的向量距离重新排序,将最相关的证据推至上下文窗口的前端。
- 上下文压缩(Context Compression):对检索到的长文本片段进行智能压缩,在保留关键信息的前提下减少冗余内容,提高上下文窗口的信息密度,使智能体能在有限的上下文空间内获取更多有效信息。
- 动态本体注入(Dynamic Ontology Injection):在智能体执行任务前,Context Loader 会根据问题意图自动从 BKN 中提取相关的本体定义(Schema),包括实体类型、属性和关系模式,注入到智能体的系统提示中,为其构建领域推理的"地图"。
- 技能路由(Skill Routing):根据当前任务自动筛选并暴露最相关的工具子集,避免智能体因选择过多而产生路径发散(详见 3.3.3 节)。
3. 评测体系与实验分析
3.1 评测框架
为系统验证 KWeaver Core 各组件的贡献度以及整体性能,我们在同一测试集口径下设计了分阶段实验方案:
数据集与样本
- 文档库:
resume/简历库,包含 118 份不同岗位方向(JAVA、C++、Golang、前端、大模型、测试、项目经理、技术支持等)的候选人简历(PDF 格式)。 - 统一测试集:消融实验与综合评测均使用同一套 145 个 HR 场景问答样本(来源于
hr_jsonl/下多个测试文件),覆盖简单信息查询、项目经验分析、跨段落综合推理三类场景,确保各项对比在同一口径下可直接比较。
评测指标
- 通过率(Accuracy):回答是否覆盖所有关键答案要点。
- 平均响应时间(Avg Latency):端到端响应延迟。
- P90 响应时间:衡量长尾稳定性。
- 平均 Token 消耗:反映推理路径的精简程度。
实验环境
- 基座模型:消融实验和综合评测统一使用 DeepSeek V3.2 作为基座模型。模型选型阶段额外引入 Qwen-Code-Plus 作为基准对比(详见 3.2 节),以验证模型能力对结果的影响。
- Embedding 模型:统一使用 BGE M3-Embedding 模型进行向量化。
3.2 KWeaver Core 实验结果总览
我们围绕模型选型、检索深度、工具组合、路径指引策略和数据复杂度五个维度,开展了多轮对比实验,核心指标包括通过率、平均响应时间、平均推理步数和平均 Token 消耗。
下表汇总了各场景的关键实验数据:
| 模型 | limit | Schema预加载 | 路径指引 | kn_search | 属性数 | 通过率 | 平均响应(s) | 平均步数 | 平均 Token |
|---|---|---|---|---|---|---|---|---|---|
| Qwen-Code-Plus | 20 | ✅ | ✅ | ✅ | 5 | 80.0% | 58.71 | 10.53 | 26,780 |
| DeepSeek V3.2 | 10 | ✅ | ✅ | ✅ | 5 | 87.59% | 40.60 | 8.60 | 18,560 |
| DeepSeek V3.2 | 20 | ✅ | ✅ | ✅ | 5 | 95.86% | 47.08 | 8.20 | 21,350 |
| DeepSeek V3.2 | 20 | ✅ | ✅ | ❌ | 5 | 99.31% | 37.82 | 7.07 | 15,420 |
| DeepSeek V3.2 | 20 | ✅ | ❌ | ❌ | 5 | 97.93% | 53.06 | 8.27 | 23,287 |
| DeepSeek V3.2 | 20 | ✅ | ❌ | ✅ | 5 | 96.55% | 53.28 | 8.93 | 19,870 |
| DeepSeek V3.2 | 20 | ❌ | ❌ | ✅ | 5 | 94.48% | 58.55 | 8.07 | 28,160 |
| DeepSeek V3.2 | 20 | ✅ | ✅ | ✅ | 15 | 90.0% | 51.34 | 9.00 | 21,447 |
从实验数据中可以提炼出以下关键发现:
- 模型选型:DeepSeek V3.2 在所有可比场景下通过率 ≥87.59%,显著优于 Qwen-Code-Plus 的 80.0%,且在同等配置(limit=10)下平均响应时间缩短约 18s,是更适合生产环境的主力推理模型。
- 检索深度:limit 从 10 提升至 20,通过率从 87.59% 提升至 95.86%,响应时间仅增加约 6.48s,证明更大的上下文覆盖对高准确率至关重要。
- 工具精简:禁用
kn_search后通过率从 95.86% 提升至 99.31%,且步数降低 13.8%(8.20→7.07),说明冗余工具会引入噪声和无效跳转。 - 路径指引与自主性:去掉路径指引但限制 2 个核心工具仍可维持 97.93%通过率;放宽到 3 个工具时通过率下降至 96.55%,表明自主模式下仍需精简工具集。
- 数据复杂度:对象类属性从 5 个增至 15 个时,通过率下降约 4.5%~10%,响应时间和步数增加约 15%,提示在复杂业务知识网络(BKN)下应考虑属性压缩或分层召回。
以下各节将围绕上述发现中的四个核心变量(检索深度、Schema 预加载、工具治理、路径指引),进行深入的消融分析。
3.3 消融实验:关键技术杠杆
我们基于同一套 145 样本测试集,逐步定位影响智能体性能的关键变量。以下四项实验分别对应了第 2 节中 KWeaver Core 架构的不同组件能力。
3.3.1 检索深度的边际效应
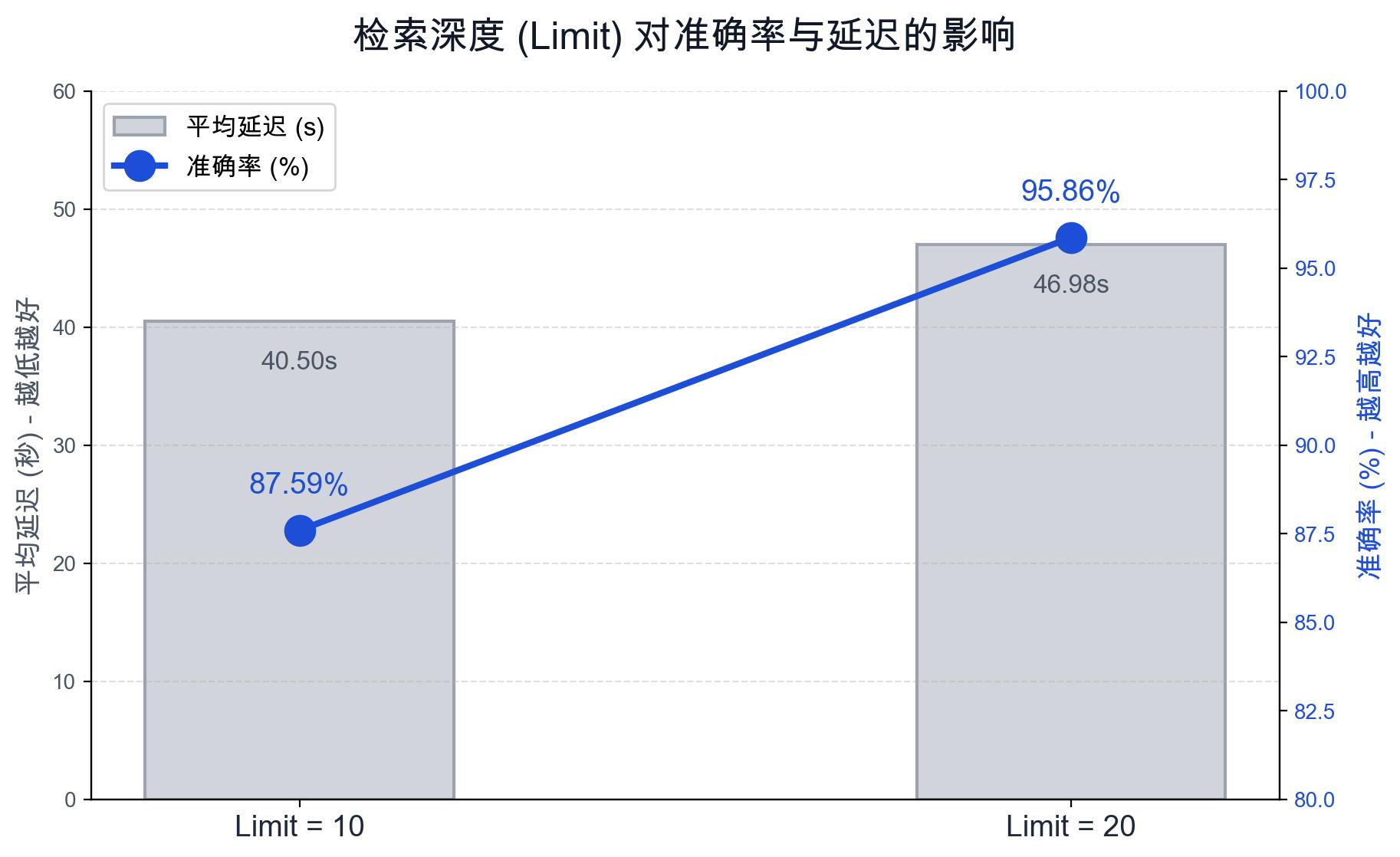
在早期迭代中,我们将检索返回的片段数量(limit)设定为 10。这足以应付大多数简单查询,但在处理需要跨多个段落综合信息的复杂案例时,准确率停滞在 87.59%。
分析失败案例后发现,关键证据往往排在检索结果的第 11 到 15 位之间。智能体因为"视野"不够宽而错失了答案。
在传统的 RAG 架构中,盲目增加检索数量往往会导致严重的"中间迷失(Lost in the Middle)"效应和信息噪声,反而容易引发大模型幻觉。然而,KWeaver Core 的平台架构赋予了我们突破这一瓶颈的"抗噪能力"。
在后续优化中,我们将 limit 提升至 20。得益于 Context Loader 的语义重排(Rerank)与上下文压缩能力,以及预加载的 Schema 帮助智能体精准锚定关键事实,KWeaver Core 有效消化了这 20 个片段的上下文信息,将通过率从 87.59% 提升至 95.86%。这带来了平均约 6.48 秒的延迟增加(约 16%),但对于企业级应用而言,这是一个可接受的延迟交换。
3.3.2 知识网络(Schema)的预加载策略
智能体在推理时经常需要知道"在这个领域里,哪些实体和关系是存在的"。如果完全依赖智能体自行探索,它可能会进行多次无效的检索尝试。
为保证与 3.2 总表完全一致,以下对照直接取自总表中两组对应配置(limit=20、开启 kn_search、无路径指引、属性数=5),仅比较 Schema 开关差异:
| 配置 | 通过率 | 平均推理步数 | 平均 Token 消耗 |
|---|---|---|---|
| 预加载 Schema | 96.55% | 8.93 步 | 19.87K |
| 不预加载 Schema | 94.48% | 8.07 步 | 28.16K |
从该组对照可以看到,Schema 预加载将 Token 消耗从 28.16K 降至 19.87K,同时通过率由 94.48% 提升至 96.55%。这表明 Schema 在该配置下能够同时提升效率与准确率,但其收益仍与路径指引、工具组合存在耦合关系。
3.3.3 工具治理:少即是多
在 Agentic 模式下,我们很容易陷入"给智能体提供尽可能多工具"的误区。然而,实验数据显示,工具集的精准裁剪对智能体性能有显著影响。
我们以"候选人项目经验查询"类任务(基于同一套 145 样本测试集)为例,在保持 limit=20、Schema 预加载和路径指引不变的条件下,对比了"包含 kn_search"与"禁用 kn_search(工具精简)"两种配置的表现:
| 工具配置 | 通过率 | 平均推理步数 | 平均 Token 消耗 | 典型失败模式 |
|---|---|---|---|---|
含 kn_search | 95.86% | 8.20 步 | 21.35K | 智能体容易进入较长的检索-过滤链路 |
禁用 kn_search(工具精简) | 99.31% | 7.07 步 | 15.42K | — |
当提供全库搜索工具时,智能体倾向于选择"看起来功能更强大"的工具,但其返回结果的噪声远高于限定范围的查询工具。智能体在消化这些噪声结果时会进入多轮反思(Reflection)循环,导致路径发散。精简工具集后,智能体被"约束"在正确的操作路径上,反而实现了一次通过(One-shot)。
这一发现揭示了一个重要原则:对于智能体而言,工具治理的核心不是"提供最多的能力",而是"消除选择歧义"。
3.3.4 关键路径指引:从"自由探索"到"有据可循"
路径指引(Path Guidance)是指在智能体执行任务前,系统为其提供明确的查询路径模板——即告诉智能体"先查什么、再查什么、如何关联"。这一策略的核心价值在于:将领域专家的经验编码为可执行的推理路线图,使智能体在面对复杂问题时不必从零摸索。
从 3.2 节的实验数据中,我们可以清晰地对比"有路径指引"与"无路径指引"两种模式下的表现差异:
| 配置 | 路径指引 | 工具数 | 通过率 | 平均响应(s) | 平均步数 | 平均 Token |
|---|---|---|---|---|---|---|
| Explore-kn_search | ✅ | 3 | 99.31% | 37.82 | 7.07 | 15,420 |
| 无路径,2 工具 | ❌ | 2 | 97.93% | 53.06 | 8.27 | 23,287 |
| 无路径,3 工具 | ❌ | 3 | 96.55% | 53.28 | 8.93 | 19,870 |
实验结果揭示了路径指引的两个关键作用:
- 降低推理成本:在工具数相近的条件下(3 个工具),有路径指引的配置(Explore-kn_search)相比无路径指引(无路径,3 工具),通过率从 96.55% 提升至 99.31%,响应时间缩短约 29%(53.28s→37.82s),Token 消耗降低约 22%(19,870→15,420)。路径指引为智能体提供了明确的"下一步该做什么"的指令,避免了在多个工具之间的犹豫和试错。
- 提升工具容忍度:没有路径指引时,智能体对工具数量仍然敏感——从 2 个增加到 3 个工具,通过率从 97.93%下降至 96.55%。而有路径指引时,即使暴露 3 个工具,智能体仍能保持 99.31%的通过率。这说明路径指引有效缓解了工具选择歧义,使智能体能够在更大的工具空间中保持稳定。
值得注意的是,即使在无路径指引的条件下,通过将工具精简至 2 个核心工具,仍可维持 97.93%的通过率。但这一"无路径"模式的代价是响应时间增加约 40%(37.82s→53.06s),Token 消耗增加约 51%(15,420→23,287)。这表明,路径指引与工具精简是两种互补的策略:路径指引通过"告诉智能体怎么走"来提升效率,工具精简通过"减少可选的岔路"来保证稳定性。在生产环境中,两者的组合可以实现最优的性能表现。
3.4 综合评测:KWeaver Core 与业界主流平台的对比
在通过消融实验确定最优配置(limit=20、Schema 预加载、路径指引、精简工具集)后,我们将测试集扩展至 145 个样本,并与业界主流平台进行横向对比。对比平台包括:开源 LLM 应用开发平台 Dify、开源 RAG 引擎 RAGFlow,以及面向企业的大模型应用平台 BiSheng(毕昇)。测试均采用 Agentic 模式。
控制变量说明:
- 基座模型与 Embedding:各平台统一使用 DeepSeek V3.2 和 BGE M3-Embedding,消除模型差异。
- 数据源:各平台导入完全相同的文档集——
resume/简历库。 - 调优程度:KWeaver Core 使用经消融实验调优后的最优配置,其他平台按照各自官方文档推荐的最佳实践配置运行,反映各平台"开箱可达的最优性能"。
结果显示,KWeaver Core 在通过率上显著领先,并在执行效率上保持了高度竞争力。
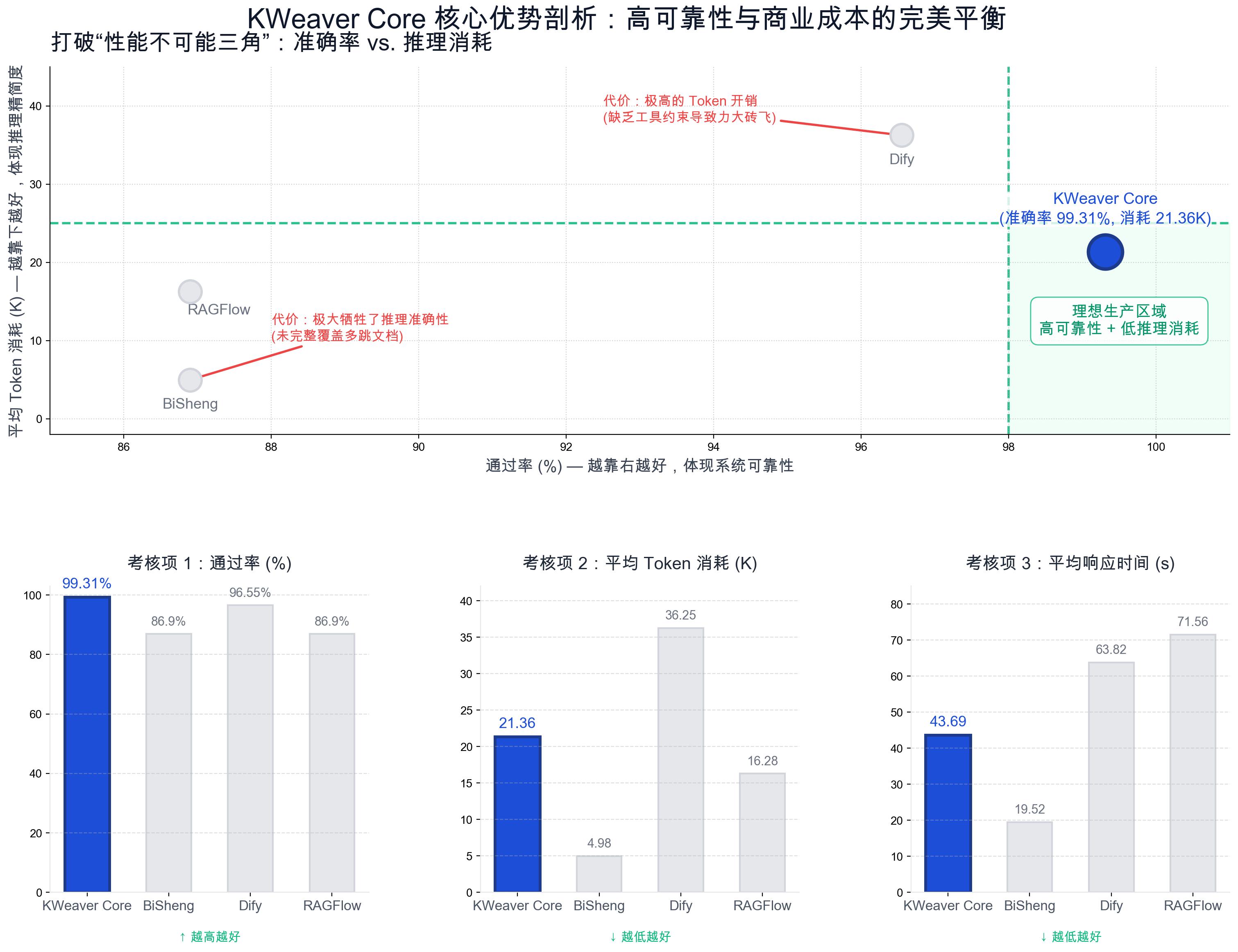
详细数据如下表所示:
| 平台指标 | KWeaver Core (v0.3.0) | BiSheng | Dify (v0.15.3) | RAGFlow (v0.17.0) |
|---|---|---|---|---|
| 通过率 (Accuracy) | 99.31% (144/145) | 86.90% (126/145) | 96.55% (140/145) | 86.90% (126/145) |
| 平均响应时间 (Avg Latency) | 43.69s | 19.52s | 63.82s | 71.56s |
| P90 响应时间 (稳定性) | 56.92s | 32.53s | 79.15s | 95.37s |
| 平均 Token 消耗 (K) | 21.36K | 4.98K | 36.25K | 16.28K |
数据来源:基于内部 145 个 HR 场景样本集(hr_jsonl/)测试结果。
KWeaver Core 核心优势深度解析:
- 绝对的可靠性优势(破局"能用与好用"的鸿沟):KWeaver Core 在 145 个复杂测试样本中通过率高达 99.31%,仅 1 例未能完全覆盖要点(极端的跨文档比对场景)。对比同为企业级业务定制的 BiSheng(86.90%)与开源 RAG 标杆 RAGFlow(86.90%),KWeaver Core 展现了在复杂业务逻辑下"高可靠、生产就绪"的统治级表现。
- "极高准确率"与"低资源消耗"的最佳平衡:传统架构往往在准确率与消耗之间艰难取舍:例如 Dify 虽然通过率达到了尚可的 96.55%,但其 Token 消耗高达 36.25K(是 KWeaver Core 的 1.7倍),且响应时间高达 63.82s。反观 BiSheng 虽然 Token 消耗极低(
4.98K),却是以严重牺牲推理深度和准确率(跌至 86.90%)换来的。KWeaver Core 平均消耗仅21.36KToken,这直接印证了 Schema 预加载和精确工具治理的威力——智能体获得了明确的"推理导航",避免了无效试错与多余的反思(Reflection),在维持最高通过率的同时,实现了推理路径的最优解。 - 极佳的应用稳定性(防御长尾发散效应):KWeaver Core 的 P90 响应时间(
56.92s)仅为平均响应时间(43.69s)的 1.3 倍,展现了非常优异的长尾稳定性。这意味着即便面对非常边缘、需要极大多跳推理的复杂请求,系统依然能在一分钟内收敛,有效避免了原生 Agent 常见的"推理路径发散"或"死循环"崩溃。
横向对比核心结论: 综合来看,Dify 属于**"高消耗换取高通过率(力大砖飞)",BiSheng 则是"牺牲准确推理换取表面上的快速低耗"**。唯有 KWeaver Core 突破了传统 RAG 架构的"性能不可能三角",在满足企业级严苛可靠性(>99%准确率)的同时,将推理成本和时间延迟控制在了高度生产可用的水平。
3.5 典型案例分析:从失败到成功
下面通过一个具体案例,展示上述技术杠杆的协同作用。
问题:"介绍下某候选人关于图数据库的经验"
这是一个典型的跨段落、多跳推理问题:某候选人的图数据库经验分散在简历的多个板块中——技能特长中提到了 NebulaGraph(一种开源图数据库),而具体的图数据库开发经验则出现在某段工作经历下的"数据服务API项目"描述中,两者之间没有显式的关键词链接。
改进前(limit=10, 无 Schema, 完整工具集)的执行路径:
- 智能体调用
kn_search搜索"候选人 图数据库",返回 10 条结果,仅匹配到技能特长中的 NebulaGraph 片段 - 智能体未找到具体项目经验,再次调用
kn_search搜索"图数据库开发经验" - 返回的结果中混入了其他候选人的技术栈描述,智能体进入反思循环
- 经过 8 步推理后,智能体给出了部分答案,但遗漏了数据服务API项目中的关键经验,回答不完整
改进后(limit=20, Schema 预加载, 精简工具集)的执行路径:
- Context Loader 预加载了简历本体 Schema
- 智能体调用限定范围的文档查询工具,一次性获取了该候选人简历的 20 个相关片段
- 得益于扩大的检索窗口,技能特长中的 NebulaGraph(排在第 4 位)和数据服务API项目描述(排在第 14 位)均被召回
- 智能体通过 Schema 中的关系定义,将技能标签与项目经验正确关联,3 步内完成完整回答
4. 结论与展望
KWeaver Core 的实践表明,要提升非结构化数据问答的可靠性,不能仅仅依赖更强的模型或更深的向量数据库。关键在于构建一个平台化的上下文工程体系。
通过 BKN 将数据"语义化",通过 Context Loader 将上下文"结构化",并通过精细的消融实验来调整检索深度和工具组合,我们在 145 个测试样本中达到了 99.31% 的高通过率,显著超越业界主流方案,验证了这一架构方向的有效性。
4.1 当前局限性
尽管取得了积极的结果,我们也清醒地认识到当前方案的局限性:
- 样本规模与领域覆盖:当前评测基于 145 个 HR 简历问答样本,覆盖了三类典型复杂场景;但对于更广泛的统计显著性结论,仍需进一步扩大样本规模和领域覆盖。后续我们计划扩展至 500+ 样本,并引入合同审查、技术文档等更多领域。
- BKN 构建成本:业务知识网络的本体定义和实体关系建模目前仍需领域专家参与,自动化程度的提升是降低落地门槛的关键。
- 领域泛化能力:在合同审查、医疗病历、法律文书等专业性更强的领域,本体 Schema 的设计和工具集的配置可能需要额外的适配工作。
- 人工调优依赖:检索深度、工具集组合等关键参数目前通过人工消融实验确定,尚未实现自动化调优。
4.2 未来方向
基于上述局限性,未来我们将致力于以下方向:
- 降低延迟:优化 Context Loader 的加载机制,探索异步预取和缓存策略,目标是将 limit=20 场景下的额外延迟降低 50% 以上。
- 增强多模态能力:利用 Dataflow,进一步提升对图表、复杂文档结构(如嵌套表格、流程图)的解析能力。
- 自动化上下文工程:探索让智能体自主判断所需上下文深度和工具组合的能力。初步方向是基于问题分类模型自动路由至预定义的配置模板,减少人工调优依赖。
- 扩大验证规模:构建覆盖更多领域和文档类型的大规模测试集,并引入第三方评估以提升结论的外部效度。